Multimodal Large Language Models for Low-Resource Languages: A Case Study for Basque
aza. 12, 2025·,,,·
0 minutuko irakurketa
Lukas Arana
Julen Etxaniz
Ander Salaberria
Gorka Azkune
Laburpena
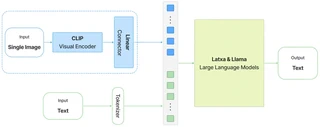
Current Multimodal Large Language Models exhibit very strong performance for several demanding tasks. While commercial MLLMs deliver acceptable performance in low-resource languages, comparable results remain unattained within the open science community. In this paper, we aim to develop a strong MLLM for a low-resource language, namely Basque. For that purpose, we develop our own training and evaluation image-text datasets. Using two different Large Language Models as backbones, the Llama-3.1-Instruct model and a Basque-adapted variant called Latxa, we explore several data mixtures for training. We show that: i) low ratios of Basque multimodal data (around 20%) are already enough to obtain solid results on Basque benchmarks, and ii) contrary to expected, a Basque instructed backbone LLM is not required to obtain a strong MLLM in Basque. Our results pave the way to develop MLLMs for other low-resource languages by openly releasing our resources.
Mota
Argitalpena
arXiv
Natural Language Processing
Large Language Models
Deep Learning
Evaluation
Multilinguality
Basque
Multimodal
Egileak
Egileak
Egileak
Egileak