Instructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
aza. 4, 2025·,,,,,,,,,,,·
0 minutuko irakurketa
Oscar Sainz
Naiara Perez
Julen Etxaniz
Joseba Fernandez de Landa
Itziar Aldabe
Iker García-Ferrero
Aimar Zabala
Ekhi Azurmendi
German Rigau
Eneko Agirre
Mikel Artetxe
Aitor Soroa
Laburpena
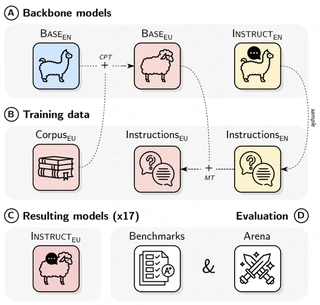
Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model. Scaling up to Llama 3.1 Instruct 70B as backbone, our model comes near frontier models of much larger sizes for Basque, without using any Basque instructions. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
Mota
Argitalpena
EMNLP 2025
Natural Language Processing
Large Language Models
Deep Learning
Multilinguality
Basque
Instruction Tuning
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak
Egileak